
[ Return ] [ Entire Thread ] [ First 100 posts ] [ Last 50 posts ]

| >> | No. 31683
31683
Almost all young women in the UK have been sexually harassed, survey finds |
| >> | No. 31684
31684
>>31683 |
| >> | No. 31685
31685
>>31684 |
| >> | No. 31686
31686
>>31684 |
| >> | No. 31687
31687
You can email the UN and ask them for the data. |
| >> | No. 31688
31688
>>31686 |
| >> | No. 31689
31689
>>31688 |
| >> | No. 31690
31690
>>31689 |
| >> | No. 31691
31691
>>31688 |
| >> | No. 31692
31692
>>31691 |
| >> | No. 31693
31693
>>31689 |
| >> | No. 31694
31694
>>31692 |
| >> | No. 31695
31695
>>31691 |
| >> | No. 31696
31696
>At the root of all this is the normalisation of the idea that a woman’s body in a public place is simply public property and young women just have to put up with it. We have to shatter that normalisation through policy and in the press if we want to change the picture |
| >> | No. 31697
31697
>>31695 |
| >> | No. 31698
31698
>>31693 |
| >> | No. 31699
31699
I don't know, I think at least part of that statistic is the result of men being expected to be the active one in any courtship and a shifting perception of what is and isn't considered appropriate. It reminds me of a gay lassm8 angrily complaining to me that she couldn't have a drink after work without being bothered by lads trying to talk to her, I saw her point but she seemed to hold it against the men despite them doing what society expects them to do. |
| >> | No. 31700
31700
I remember once when I was younger, I think I was at uni, there was a woman walking ahead of me in the street, she looked back a couple of times but I thought nothing of it. Then I tripped on a paving stone and made a stumbling noise, at which I heard her audibly gasp. I had an impulse to explain that I wasn't following her but realised that would just have made it worse, so I crossed the street and sped up so I was in front of her so she could see me. I know it wasn't remotely my fault that she felt threatened or like she was being followed by me, but I still felt fucking awful and it's stuck with me. It was probably the first time I really thought about it from a woman's perspective. |
| >> | No. 31701
31701
>>31698 |
| >> | No. 31702
31702
>>31701 |
| >> | No. 31705
31705
97% of women report sexual harassment, but it doesn't say what that harassment entailed. Are they being groped, touched, verbally harassed or is simply being unattractive enough for a women to think you speaking to them is harassment? We need to know where the bar is do something about it. |
| >> | No. 31706
31706
>>31702 |
| >> | No. 31707
31707
To anyone doubting the numbers, ask the women in your life about their experiences. The world is full of awful perverts who mostly get away with it. Being wanked at in the street or having an erection rubbed against your arse on the Tube or getting a hand up your skirt in a nightclub is just a normal part of life for women. |
| >> | No. 31708
31708
>>31707 |
| >> | No. 31709
31709
>>31700 |
| >> | No. 31710
31710
Women in the Western world are amongst the most privileged and least endangered demographics out of the entire human population. First world feminism is nothing but petit bourgeois power politics. |
| >> | No. 31711
31711
>>31710 |
| >> | No. 31712
31712
>>31709 |
| >> | No. 31713
31713
>>31711 |
| >> | No. 31714
31714
>>31713 |
| >> | No. 31715
31715
>>31711 |
| >> | No. 31716
31716
Observation of people has taught me that people label it as sexual harassment when a sexual advancement is rejected that they would have been fine or even fantasised about had it been a person they were into. If you believed everything you read about what is sexual harassment. You would never be able to procreate. This is perhaps why internet porn has turned to incest because they are the only women young men are taught they can engage without volatile rejection. |
| >> | No. 31717
31717
>>31715 |
| >> | No. 31718
31718
>>31716 |
| >> | No. 31719
31719
>>31717 |
| >> | No. 31720
31720
>>31717 |
| >> | No. 31721
31721
>>31720 |
| >> | No. 31722
31722
So what sexual harassment stats do you lads actually believe then? |
| >> | No. 31723
31723
This is all just a smokescreen for the anti-protesting laws they're planning to pass. |
| >> | No. 31724
31724
>>31717 |
| >> | No. 31725
31725
>>31721 |
| >> | No. 31726
31726
>>31725 |
| >> | No. 31728
31728
>>31726 |
| >> | No. 31729
31729
>>31721 |
| >> | No. 31730
31730
Open question lads: Have any of you ever turned down a female's advances on you? How did she react? |
| >> | No. 31731
31731
>>31721 |
| >> | No. 31732
31732
>>31730 |
| >> | No. 31733
31733
>>31730 |
| >> | No. 31734
31734
>>31731 |
| >> | No. 31735
31735
>>31728 |
| >> | No. 31736
31736
>>31735 |
| >> | No. 31737
31737
>>31735 |
| >> | No. 31739
31739
>>31738 |
| >> | No. 31740
31740
>>31738 |
| >> | No. 31741
31741
>>31740 |
| >> | No. 31742
31742
>>31736 |
| >> | No. 31744
31744
>>31740 |
| >> | No. 31745
31745
>>31744 |
| >> | No. 31746
31746
>>31743 |
| >> | No. 31747
31747
>>31706 |
| >> | No. 31748
31748
>>31743 |
| >> | No. 31749
31749
Sekuhara.png 
https://docs.cdn.yougov.com/qepiqi9xaf/YouGov%20Sexual%20harassment.pdf |
| >> | No. 31750
31750
>>31744 |
| >> | No. 31751
31751
1200.jpg 
>>31746 |
| >> | No. 31752
31752
>>31751 |
| >> | No. 31753
31753
>>31752 |
| >> | No. 31754
31754
>>31753 |
| >> | No. 31755
31755
>>31749 |
| >> | No. 31756
31756
>>31755 |
| >> | No. 31757
31757
>>31749 |
| >> | No. 31758
31758
>>31749 |
| >> | No. 31759
31759
>>31758 |
| >> | No. 31760
31760
>>31757 |
| >> | No. 31761
31761
>>31749 |
| >> | No. 31762
31762
>>31761 |
| >> | No. 31763
31763
>>31761 |
| >> | No. 31764
31764
What happened to flashing anyway? It seemed to be all the rage in the 00s but these days there's not a sausage outside of naked protests. I'm not saying I've seen any blokes in trench coats but there were plenty more tits back in my day. |
| >> | No. 31765
31765
>>31763 |
| >> | No. 31766
31766
>>31765 |
| >> | No. 31767
31767
>>31765 |
| >> | No. 31768
31768
Sekuhara 2.png 
Ah, here we go. |
| >> | No. 31769
31769
>>31756 |
| >> | No. 31770
31770
>>31762 |
| >> | No. 31771
31771
>>31769 |
| >> | No. 31772
31772
>>31771 |
| >> | No. 31773
31773
>>31742 |
| >> | No. 31774
31774
>>31773 |
| >> | No. 31775
31775
>>31772 |
| >> | No. 31776
31776
>>31771 |
| >> | No. 31777
31777
>>31775 |
| >> | No. 31778
31778
Can you maybe take a break from arguing about this pointless distraction to sign this petition please? |
| >> | No. 31779
31779
>>31777 |
| >> | No. 31780
31780
Not that it particularly matters, but are there any women in this thread? |
| >> | No. 31781
31781
>>31780 |
| >> | No. 31782
31782
>>31781 |
| >> | No. 31783
31783
>>31782 |
| >> | No. 31784
31784
>>31780 |
| >> | No. 31785
31785
>>31784 |
| >> | No. 31786
31786
>>31785 |
| >> | No. 31787
31787
>>31785 |
| >> | No. 31788
31788
>>31785 |
| >> | No. 31789
31789
Green Party peer calls for 6pm curfew for men after the disappearance of Sarah Everard |
| >> | No. 31790
31790
>>31789 |
| >> | No. 31791
31791
>>31789 |
| >> | No. 31792
31792
>>31790 |
| >> | No. 31793
31793
>>31791 |
| >> | No. 31794
31794
>>31792 |
| >> | No. 31795
31795
There's plenty of places you won't find me walking around at night. Common sense that, and it's only sheltered middle class dickheads who bring out the "victim blaming" line about that. |
| >> | No. 31799
31799
The sad thing is that you can tell men how to help women feel safer but the ones that are a danger aren't the ones that are going to implement or follow any of that advice. |
| >> | No. 31800
31800
>>31795 |
| >> | No. 31801
31801
>Street harassment is how men mark out public spaces as their own, making women into trespassers on male territory. Behavioural psychologists have observed how male pedestrians crowd women’s personal space at cashpoints and traffic lights, how all-male groups take up more pavement space, and how men make more antisocial noises in public than women, considering it more acceptable to speak on mobile phones at checkouts or in train carriages. Women are more distressed than men by such unwanted public noise, and by having to challenge its perpetrators. We don’t know how these encounters might escalate. |
| >> | No. 31802
31802
>>31800 |
| >> | No. 31803
31803
>>31801 |
| >> | No. 31804
31804
>>31799 |
| >> | No. 31805
31805
>>31800 |
| >> | No. 31806
31806
>>31805 |
| >> | No. 31807
31807
>>31806 |
| >> | No. 31808
31808
>>31801 |
| >> | No. 31809
31809
>>31804 |
| >> | No. 31810
31810
>>31801 |
| >> | No. 31811
31811
>>31810 |
| >> | No. 31812
31812
>>31811 |
| >> | No. 31813
31813
>>31809 |
| >> | No. 31814
31814
>>31792 |
| >> | No. 31815
31815
>>31814 |
| >> | No. 31817
31817
>I genuinely wouldn't be surprised if the brain rot that the Guardian regularly churns out pushes more people towards the right than the Mail does. |
| >> | No. 31818
31818
Much as It's a given that nobody, man or woman, deserves to become a victim of any kind of physical violence at all, our streets are safe. Crime statistics show Britain as a safe place to live, and that includes women walking home at night. Women can't just feel safe, they are safe. And if you need any more convincing, look at figures of (sexual) physical violence in many third-world shitehole major cities. They have a problem with street violence. We, for all intents and purposes, do not. |
| >> | No. 31819
31819
>>31818 |
| >> | No. 31821
31821
>>31819 |
| >> | No. 31822
31822
>>31819 |
| >> | No. 31823
31823
>>31819 |
| >> | No. 31824
31824
>>31822 |
| >> | No. 31825
31825
>>31822 |
| >> | No. 31826
31826
>>31825 |
| >> | No. 31827
31827
>>31826 |
| >> | No. 31828
31828
>>31826 |
| >> | No. 31829
31829
>>31818 |
| >> | No. 31830
31830
>>31829 |
| >> | No. 31831
31831
>>31818 |
| >> | No. 31832
31832
I'm a man and I don't feel safe walking home, not everywhere. There are parts of my town I simply wouldn't go at night, places I probably wouldn't even drive through. |
| >> | No. 31833
31833
>>31829 |
| >> | No. 31834
31834
>>31832 |
| >> | No. 31835
31835
It's almost as if people feel like crimes that affect people like them are proportionally higher or need to be prioritised more. |
| >> | No. 31836
31836
>>31834 |
| >> | No. 31838
31838
>>31823 |
| >> | No. 31840
31840
>>31838 |
| >> | No. 31842
31842
>>31830 |
| >> | No. 31852
31852
>>31840 |
| >> | No. 31853
31853
>>31852 |
| >> | No. 31856
31856
>>31842 |
| >> | No. 31861
31861
>>31856 |
| >> | No. 31862
31862
>>31856 |
| >> | No. 31868
31868
>>31862 |
| >> | No. 31869
31869
>>31862 |
| >> | No. 31872
31872
>>31869 |
| >> | No. 31873
31873
>>31872 |
| >> | No. 31874
31874
>>31873 |
| >> | No. 31875
31875
>>31874 |
| >> | No. 31876
31876
time_cube_graphic.gif  >>31875 |
| >> | No. 31879
31879
>>31876 |
| >> | No. 31880
31880
>>31879 |
| >> | No. 31882
31882
>>31879 |
| >> | No. 31884
31884
>>31875 |
| >> | No. 31887
31887
Our Lord and Steven.png 
>>31884 |
| >> | No. 31888
31888
>>31887 |
| >> | No. 31889
31889
I mean, if you've got sone kind of stake in denying that races or sexism have actual biological differences, then I have to assume you're basically the same thing as a flat earther or anti-vaxxer, but woke. |
| >> | No. 31891
31891
>>31889 |
| >> | No. 31893
31893
>>31889 |
| >> | No. 31894
31894
>>31884 |
| >> | No. 31900
31900
q3389qf97hh31.jpg 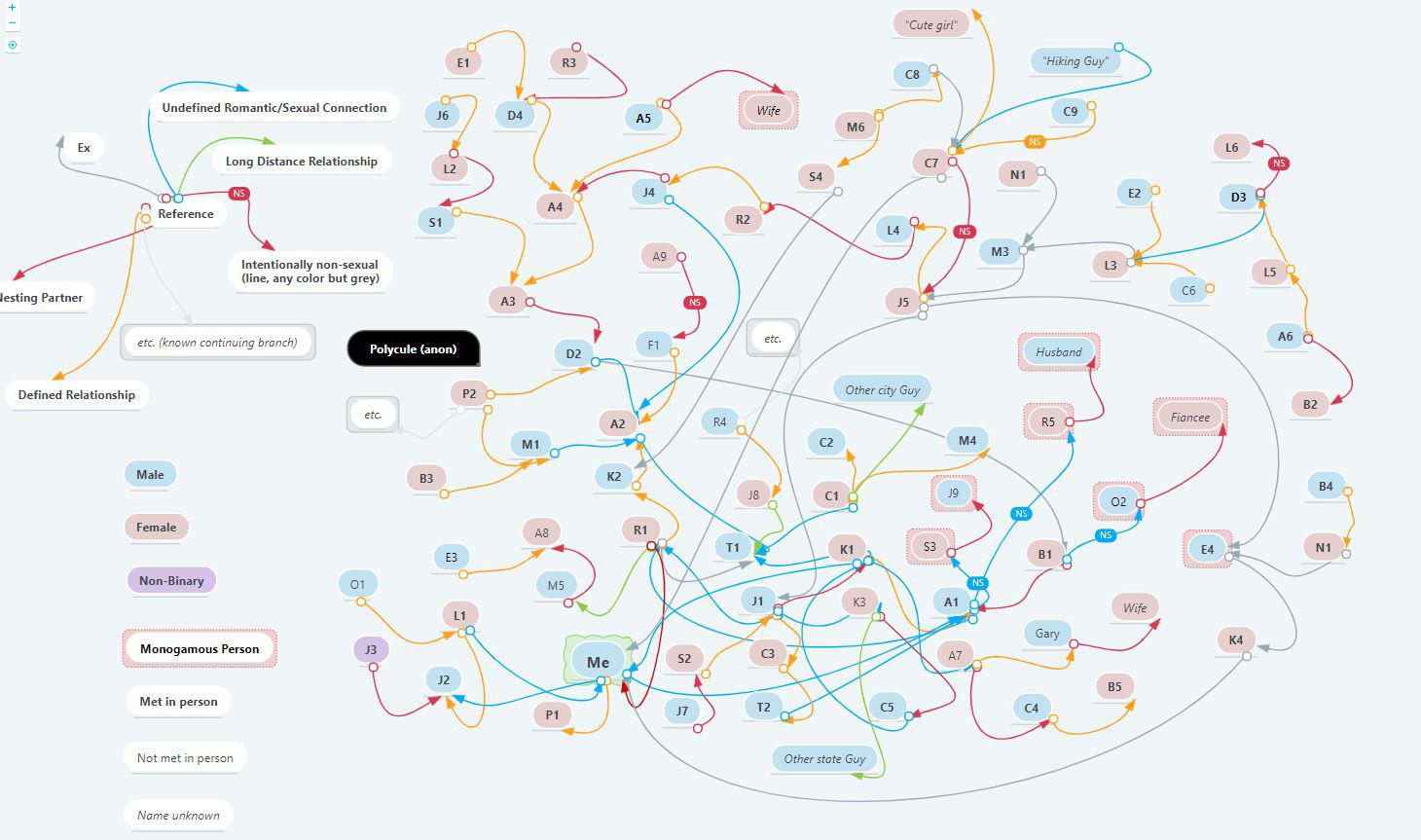
>>31894 |
| >> | No. 31902
31902
>>31893 |
| >> | No. 31904
31904
EudW2PZXcAUQbhY.jpg 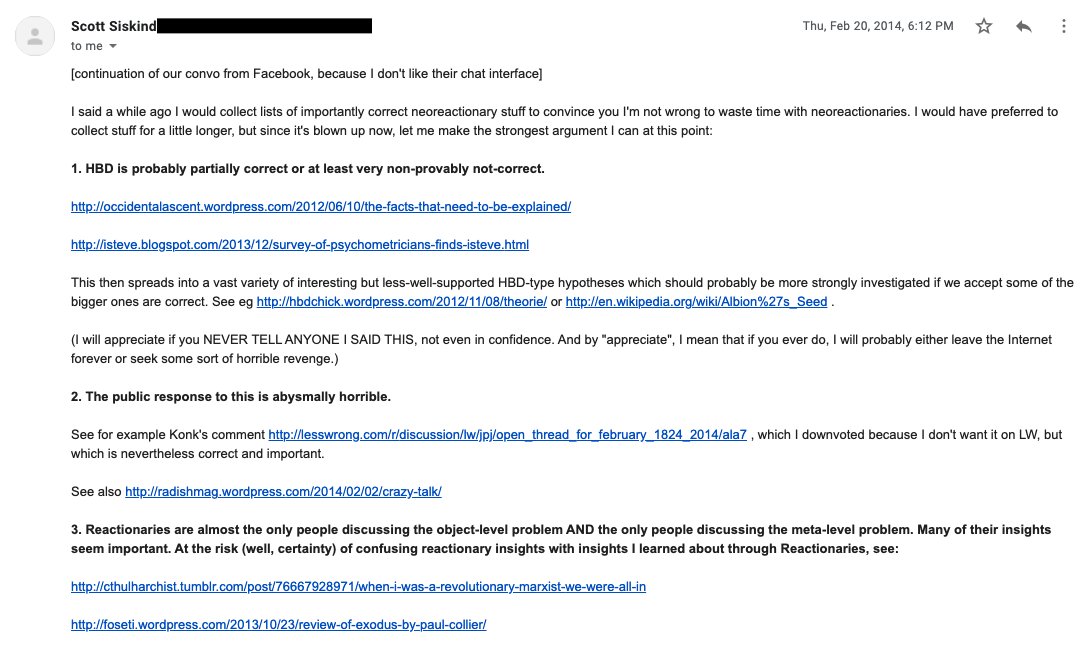
>>31894 |
| >> | No. 31907
31907
>>31902 |
| >> | No. 31908
31908
>>31907 |
| >> | No. 31909
31909
>>31907 |
| >> | No. 31910
31910
>>31909 |
| >> | No. 31911
31911
How has someone being murdered ended up with me being told I should tell my mates off for looking at a girl's arse? That seems like a valid area for discussion in of itself but I'm not comfortable with the association. |
| >> | No. 31912
31912
>>31910 |
| >> | No. 31913
31913
>>31910 |
| >> | No. 31914
31914
>>31904 |
| >> | No. 31917
31917
>>31914 |
| >> | No. 31918
31918
>>31911 |
| >> | No. 31919
31919
>>31917 |
| >> | No. 31920
31920
Women are indistinguishable biologically from men which is why I believe we should remove the outdated sexist segregation in sports. |
| >> | No. 31921
31921
>>31919 |
| >> | No. 31922
31922
>>31921 |
| >> | No. 31923
31923
>>31922 |
| >> | No. 31924
31924
>>31923 |
| >> | No. 31925
31925
>>31902 |
| >> | No. 31926
31926
>>31925 |
| >> | No. 31927
31927
listing.jpg 
There's something quite eerie about phone lights at vigils replacing candles and lighters. |
| >> | No. 31928
31928
>>31925 |
| >> | No. 31929
31929
>>31928 |
| >> | No. 31930
31930
>>31929 |
| >> | No. 31931
31931
>>31925 |
| >> | No. 31932
31932
On the positive side, the police violence last night has brought some attention to the policing act that Patel's bringing in. |
| >> | No. 31933
31933
>>31932 |
| >> | No. 31934
31934
If we discuss gender differences, one mistake we must not make is to have our cake and eat it too when it comes to painting men as the defective, violence-prone gender. |
| >> | No. 31935
31935
https://www.theguardian.com/commentisfree/2021/mar/14/sarah-everard-misogyny-men-violence-death-women |
| >> | No. 31937
31937
_117493708_ibrox_reuters-1.jpg 
>>31933 |
| >> | No. 31938
31938
>>31933 |
| >> | No. 31939
31939
>>31929 |
| >> | No. 31941
31941
>>31888 |
| >> | No. 31942
31942
>>31941 |
| >> | No. 31943
31943
>>31942 |
| >> | No. 31944
31944
>>31933 |
| >> | No. 31945
31945
>>31942 |
| >> | No. 31946
31946
>>31941 |
| >> | No. 31948
31948
Untitled.png 
>>31944 |
| >> | No. 31951
31951
>>31948 |
| >> | No. 31952
31952
I know we've veered off onto domestic violence rather than sexual harassment here, but I imagine this situation would be exactly the same in reverse if we lived in a mirror universe where women are the ones who are expected to make the first move on men, and therefore the ones effectively made to compete for a mate. |
| >> | No. 31954
31954
>>31952 |
| >> | No. 31955
31955
>>31954 |
| >> | No. 31956
31956
>>31951 |
| >> | No. 31957
31957
>>31956 |
| >> | No. 31958
31958
>>31951 |
| >> | No. 31959
31959
>>31955 |
| >> | No. 31960
31960
>>31958 |
| >> | No. 31961
31961
This whole "men as a gender" thing is so meaningless. Don't teach women to stay safe, teach men not to harass. What does it even mean? |
| >> | No. 31963
31963
>>31961 |
| >> | No. 31964
31964
>>31963 |
| >> | No. 31967
31967
>>31964 |
| >> | No. 31968
31968
>>31964 |
| >> | No. 31969
31969
>>31911 |
| >> | No. 31970
31970
>>31946 |
| >> | No. 31971
31971
>>31970 |
| >> | No. 31972
31972
>>31968 - I think opinions like this are quite regressive. They make it incredibly hard to have a conversation about the topic without getting sidetracked by someone tripping you up for not padding every single sentiment with a clarification. Is that your intention? |
| >> | No. 31973
31973
>>31969 |
| >> | No. 31974
31974
>>31971 |
| >> | No. 31975
31975
I'm starting to find the assumption that all men are attracted to women to be irritating. I understand it of course, most men are straight, you casually say "Men" when you really mean "Most men" not "all men" and so on. But I'm not straight, I'm gay. |
| >> | No. 31976
31976
>>31975 |
| >> | No. 31977
31977
>>31972 |
| >> | No. 31978
31978
>>31974 |
| >> | No. 31979
31979
>>31978 |
| >> | No. 31980
31980
>>31972 |
| >> | No. 31981
31981
>>31975 |
| >> | No. 31982
31982
>>31979 |
| >> | No. 31983
31983
>>31982 |
| >> | No. 31984
31984
EwbU15PWYAMtILa.jpg 
Hmmmm. |
| >> | No. 31985
31985
And now the "crisis actor" brainworms have reached here. Well done everyone. |
| >> | No. 31986
31986
>>31968 |
| >> | No. 31987
31987
>>31983 |
| >> | No. 31988
31988
>>31984 |
| >> | No. 31989
31989
>>31982 |
| >> | No. 31990
31990
>>31986 |
| >> | No. 31991
31991
>>31989 |
| >> | No. 31992
31992
>>31985 |
| >> | No. 31993
31993
>>31982 |
| >> | No. 31994
31994
>>31993 |
| >> | No. 31995
31995
educate.png 
>>31994 |
| >> | No. 31996
31996
You pair have made me a misandrist. |
| >> | No. 31997
31997
>>31994 |
| >> | No. 31998
31998
>>31997 |
| >> | No. 31999
31999
The only reason this news story gained traction and there is protest is that women were bored at home with lockdown. |
| >> | No. 32000
32000
>>31999 |
| >> | No. 32001
32001
>>32000 |
| >> | No. 32002
32002
>>32000 |
| >> | No. 32003
32003
>>32001 |
| >> | No. 32004
32004
>>32003 |
| >> | No. 32005
32005
>>32003 |
| >> | No. 32006
32006
>>32003 |
| >> | No. 32007
32007
>>32005 |
| >> | No. 32008
32008
>>31977 |
| >> | No. 32009
32009
Let's imagine that all big cities have a sort of large, vicious Pterodactyl flying overhead. It likes people of smaller stature, and once it grabs you, there's nothing you can do. The chances of it coming down and grabbing you, as an individual, are infinitesimally small, but if it happens then you will certainly die a horrible death. |
| >> | No. 32010
32010
>>32007 |
| >> | No. 32011
32011
>>32010 |
| >> | No. 32012
32012
>>32011 |
| >> | No. 32013
32013
>>32012 |
| >> | No. 32014
32014
>>32013 |
| >> | No. 32015
32015
>>32014 |
| >> | No. 32016
32016
>>32014 |
| >> | No. 32017
32017
>>32016 |
| >> | No. 32018
32018
>>32017 |
| >> | No. 32019
32019
>>32016 |
| >> | No. 32020
32020
>>32019 |
| >> | No. 32021
32021
>>32019 |
| >> | No. 32022
32022
>>32016 |
| >> | No. 32023
32023
>>32022 |
| >> | No. 32024
32024
I'm on the side of the lad who thinks the new policing law is important. I sympathise that with the way the media is controlled and run in this country (not Jews) it's difficult to recognise what you should be paying attention to, but you have to see through the wood for the pterodactyls. |
| >> | No. 32025
32025
>>32020 |
| >> | No. 32026
32026
>>32023 |
| >> | No. 32027
32027
>>32009 |
| >> | No. 32028
32028
>>32027 |
| >> | No. 32029
32029
>>32025 |
| >> | No. 32030
32030
>>32028 |
| >> | No. 32031
32031
>>32028 |
| >> | No. 32032
32032
>>32027 |
| >> | No. 32035
32035
>>32032 |
| >> | No. 32037
32037
>>32035 |
| >> | No. 32041
32041
>>32037 |
| >> | No. 32042
32042
>>32041 |
| >> | No. 32045
32045
>>32041 |
| >> | No. 32046
32046
>>32008 |
| >> | No. 32047
32047
>>32010 |
| >> | No. 32050
32050
>>32027 |
| >> | No. 32051
32051
All I know is that the #CurfewForAllMen hashtag has raised awareness for the issue, which is good. |
| >> | No. 32054
32054
>>32051 |
| >> | No. 32056
32056
>>32054 |
| >> | No. 32058
32058
>>31990 |
| >> | No. 32059
32059
>>32058 |
| >> | No. 32061
32061
>>32050 |
| >> | No. 32062
32062
>>32061 |
| >> | No. 32063
32063
>>32059 |
| >> | No. 32064
32064
>>32058 |
| >> | No. 32065
32065
>>32064 |
| >> | No. 32068
32068
>>32065 |
| >> | No. 32071
32071
>>32068 |
| >> | No. 32073
32073
Going to be very interesting hearing what this copper has to say for himself. |
| >> | No. 32074
32074
Don't say it won't ever happen.png 
>I'm not really sure what relevance this has to women being harassed, beaten, raped and murdered. |
| >> | No. 32075
32075
>>32074 |
| >> | No. 32076
32076
>>32074 |
| >> | No. 32078
32078
>>32076 |
| >> | No. 32079
32079
>>32076 |
| >> | No. 32080
32080
>>32079 |
| >> | No. 32081
32081
>>32078 |
| >> | No. 32082
32082
>>32076 |
| >> | No. 32083
32083
>>32082 |
| >> | No. 32084
32084
>>32083 |
| >> | No. 32085
32085
>>32082 |
| >> | No. 32086
32086
>>32083 |
| >> | No. 32088
32088
>>32086 |
| >> | No. 32090
32090
>>32085 |
| >> | No. 32093
32093
>Well why didn't you say so earlier? If I'd known that was the case I'd have started posting victim-blaming polite nonsense earlier. |
| >> | No. 32094
32094
>>32093 |
| >> | No. 32098
32098
>>32094 |
| >> | No. 32102
32102
>>32090 |
| >> | No. 32104
32104
>>32083 |
| >> | No. 32105
32105
>>32071 |
| >> | No. 32109
32109
>>32079 |
| >> | No. 32111
32111
>>32090 |
| >> | No. 32112
32112
>>32109 |
| >> | No. 32114
32114
>>32111 |
| >> | No. 32116
32116
>>32112 |
| >> | No. 32118
32118
>>32112 |
| >> | No. 32119
32119
>>32114 |
| >> | No. 32122
32122
>>32112 |
| >> | No. 32123
32123
>>>>32119 |
| >> | No. 32124
32124
I'd just like to point out that, as a psychopath, not all of us are after going out and murdering people. I know I could probably do it and do it well enough to get away with it, but with little to no personal gain it's simply not worth the risk. I'd imagine the majority of that 1% of psychopaths feel the same way. |
| >> | No. 32125
32125
>>32123 |
| >> | No. 32126
32126
>>32124 |
| >> | No. 32127
32127
>>32125 |
| >> | No. 32128
32128
As has been pointed out in this thread is women by all accounts are very safe, safer than they have ever been and safer than men (even though not being safe is treated as a woman’s problem, this is because women complain and men don’t (I’ll explain)). |
| >> | No. 32129
32129
Get a load of all this evopsych. Fuck me. |
| >> | No. 32130
32130
>>32127 |
| >> | No. 32131
32131
>>32130 |
| >> | No. 32132
32132
>>32130 |
| >> | No. 32133
32133
>>32128 |
| >> | No. 32134
32134
>>32132 |
| >> | No. 32135
32135
>>32134 |
| >> | No. 32136
32136
>>32135 |
| >> | No. 32137
32137
>>32135 |
| >> | No. 32138
32138
>>32137 |
| >> | No. 32139
32139
>>32138 |
| >> | No. 32140
32140
Beta Picard.jpg 
>>32134 |
| >> | No. 32141
32141
>>32140 |
| >> | No. 32143
32143
>>32138 |
| >> | No. 32144
32144
>>32137 |
| >> | No. 32147
32147
>>32141 |
| >> | No. 32149
32149
>>32144 |
| >> | No. 32150
32150
>>32149 |
| >> | No. 32151
32151
>>32150 |
| >> | No. 32152
32152
>>32149 |
| >> | No. 32153
32153
>>32147 |
| >> | No. 32154
32154
We've managed to float pretty far away from the point in this thread. We've gone from "97% of women have been sexually harassed" to "only a fraction of a 1% subset of people are murdering women at night, so there's nothing we can do" |
| >> | No. 32155
32155
>>32154 |
| >> | No. 32156
32156
>>32154 |
| >> | No. 32157
32157
dougal-featured-1024x598.jpg 
>>32156 |
| >> | No. 32158
32158
>>32155 |
| >> | No. 32159
32159
>>32156 |
| >> | No. 32160
32160
>>32159 |
| >> | No. 32161
32161
Screenshot 2021-03-12.png  >>32160 |
| >> | No. 32162
32162
DarkAge.jpg 
>>32161 |
| >> | No. 32163
32163
>>32161 |
| >> | No. 32164
32164
>>32161 |
| >> | No. 32166
32166
a48673eb-618a-4732-a413-9e2ddda0b849.png 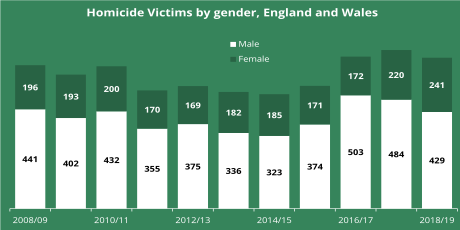 >>32164 |
| >> | No. 32167
32167
>>32166 |
| >> | No. 32168
32168
>>32167 |
| >> | No. 32169
32169
>>32163 |
| >> | No. 32170
32170
>>32169 |
| >> | No. 32171
32171
>>32169 |
| >> | No. 32172
32172
EwnEKU8W8AIncEk.jpg 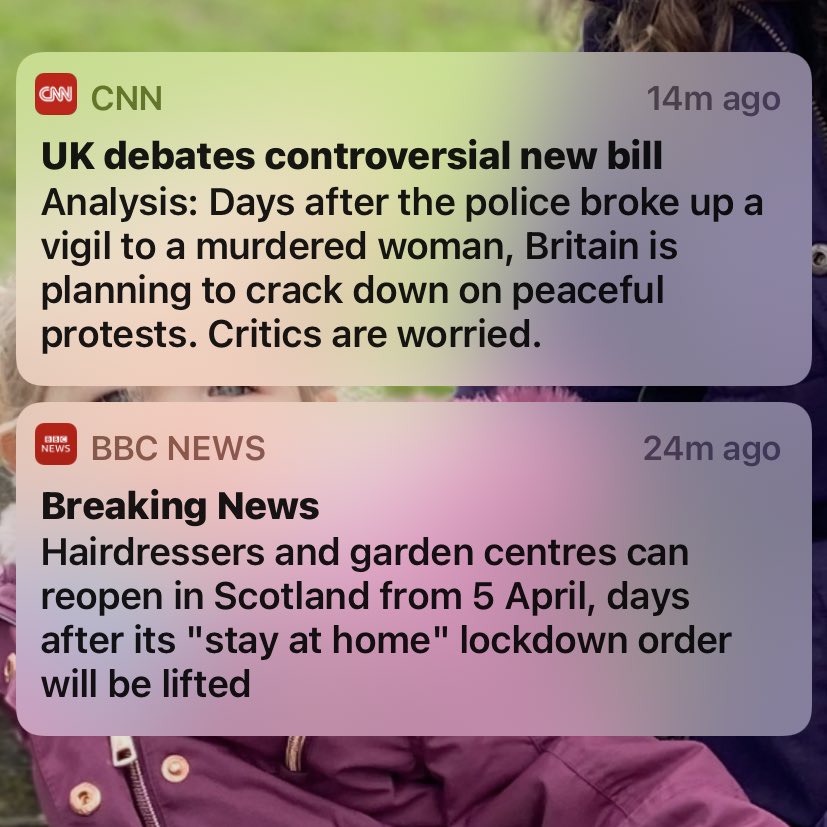
You're all still arguing over who should get to play the victim card? Great. |
| >> | No. 32187
32187
>>32169 |
| >> | No. 32194
32194
>>32187 |
| >> | No. 32196
32196
>>32194 |
| >> | No. 32199
32199
>>32196 |
| >> | No. 32200
32200
>>32196 |
| >> | No. 32202
32202
>>32199 |
| >> | No. 32204
32204
>>32202 |
| >> | No. 32205
32205
>>32202 |
| >> | No. 32206
32206
>>32202 |
| >> | No. 32208
32208
>>32205 |
| >> | No. 32209
32209
>>32202 |
| >> | No. 32210
32210
>>32208 |
| >> | No. 32211
32211
>>32209 |
| >> | No. 32212
32212
>>32209 |
| >> | No. 32213
32213
>>32210 |
| >> | No. 32214
32214
>>32213 |
| >> | No. 32215
32215
>>32208 |
| >> | No. 32216
32216
>>32212 |
| >> | No. 32217
32217
>>32216 |
| >> | No. 32218
32218
>>32217 |
| >> | No. 32219
32219
>>32218 |
| >> | No. 32220
32220
>>32219 |
| >> | No. 32221
32221
>>32220 |
| >> | No. 32222
32222
>>32221 |
| >> | No. 32223
32223
>>32218 |
| >> | No. 32225
32225
>>32222 |
| >> | No. 32226
32226
>>32187 |
| >> | No. 32227
32227
>>32225 |
| >> | No. 32228
32228
>>32225 |
| >> | No. 32230
32230
40555616-9369363-image-a-16_1615930594496.jpg 
A VOTE FOR THE TORIES IS A VOTE SUPPORTING RAPISTS. |
| >> | No. 32231
32231
>>32230 |
| >> | No. 32232
32232
>>32230 |
| >> | No. 32233
32233
What women want and what women say is a Venn diagram in which the two circles aren't just separate, they're on two different pages. |
| >> | No. 32234
32234
>>32232 |
| >> | No. 32240
32240
>>32231 |
| >> | No. 32241
32241
>>32225 |
| >> | No. 32245
32245
21a3dd0b5c711951e9aa343b8bc66928.jpg 
>>32233 |
| >> | No. 32248
32248
>>32245 |
| >> | No. 32254
32254
>>32248 |
| >> | No. 32257
32257
>>32248 |
| >> | No. 32258
32258
>>32257 |
| >> | No. 32259
32259
>>32258 |
| >> | No. 32260
32260
>>32259 |
| >> | No. 32261
32261
>>32259 |
| >> | No. 32263
32263
>>32260 |
| >> | No. 32264
32264
>>32261 |
| >> | No. 32265
32265
>>32263 |
| >> | No. 32266
32266
>>32264 |
| >> | No. 32267
32267
>>32264 |
| >> | No. 32273
32273
>>32233 |
| >> | No. 32274
32274
>>32273 |
| >> | No. 32276
32276
>>32233 |
| >> | No. 32282
32282
>>32276 |
| >> | No. 32285
32285
>>32282 |
| >> | No. 32286
32286
>>32285 |
| >> | No. 32287
32287
>>32286 |
| >> | No. 32288
32288
such-women-copy.jpg 
>>32286 |
| >> | No. 32296
32296
>>32286 |
| >> | No. 32309
32309
>>32288 |
| >> | No. 32311
32311
>>32309 |
| >> | No. 32312
32312
>>32311 |
| >> | No. 32315
32315
>>32311 |
| >> | No. 32316
32316
>>32315 |
| >> | No. 32319
32319
>>32311 |
| >> | No. 32320
32320
>>32319 |
| >> | No. 32321
32321
>>32309 |
| >> | No. 32322
32322
161313473_3878598082216737_8549376728875461351_n.jpg 
Apparently it's fine for women to come out with blanket statements like this about men, but if you applied the same line of reasoning to Islam and terrorism it's beyond the pale. |
| >> | No. 32323
32323
>>32322 |
| >> | No. 32324
32324
>>32322 |
| >> | No. 32325
32325
>>32323 |
| >> | No. 32326
32326
>>32323 |
| >> | No. 32327
32327
>>32322 |
| >> | No. 32328
32328
>>32327 |
| >> | No. 32329
32329
>>32328 |
| >> | No. 32330
32330
>>32322 |
| >> | No. 32331
32331
>>32329 |
| >> | No. 32332
32332
>>32324 |
| >> | No. 32333
32333
>>32330 |
| >> | No. 32334
32334
>>32332 |
| >> | No. 32335
32335
>>32330 |
| >> | No. 32336
32336
>>32333 |
| >> | No. 32337
32337
>>32326 |
| >> | No. 32338
32338
>>32335 |
| >> | No. 32339
32339
>>32335 |
| >> | No. 32342
32342
>>32339 |
| >> | No. 32343
32343
>>32342 |
| >> | No. 32344
32344
>>32343 |
| >> | No. 32346
32346
This is idiotic. Real fisherpersons completely agree with the idea that the patriarchal system is also unfair on men in some ways. It's not glossed over, it's an active part of the doctrine. You're talking a lot but you're not saying anything. |
| >> | No. 32347
32347
>>32346 |
| >> | No. 32348
32348
>>32347 |
| >> | No. 32349
32349
>>32346 |
| >> | No. 32350
32350
Mods, have you scientifically crafted this sodding thread in a lab in order to make me post something mental? Like a useless geek version of Bruce Banner? |
| >> | No. 32351
32351
>>32342 |
| >> | No. 32352
32352
>>32349 |
| >> | No. 32353
32353
>>32346 |
| >> | No. 32355
32355
>>32353 |
| >> | No. 32356
32356
>>32351 |
| >> | No. 32358
32358
>>32352 |
| >> | No. 32359
32359
>>32350 |
| >> | No. 32360
32360
>>32356 |
| >> | No. 32361
32361
>>32360 |
| >> | No. 32362
32362
>>32359 |
| >> | No. 32363
32363
>>32361 |
| >> | No. 32364
32364
>>32355 |
| >> | No. 32366
32366
>>32360 |
| >> | No. 32373
32373
>>32356 |
| >> | No. 32374
32374
>>32373 |
| >> | No. 32375
32375
>>32374 |
| >> | No. 32376
32376
>>32375 |
| >> | No. 32377
32377
>>32376 |
| >> | No. 32378
32378
>>32377 |
| >> | No. 32379
32379
>>32376 |
| >> | No. 32380
32380
>>32346 |
| >> | No. 32381
32381
>>32378 |
| >> | No. 32382
32382
>>32373 |
| >> | No. 32383
32383
>>32382 |
| >> | No. 32384
32384
>>32382 |
| >> | No. 32386
32386
>>32384 |
| >> | No. 32387
32387
>>32386 |
| >> | No. 32388
32388
>An off-duty police officer who attacked a terrified woman as she walked home alone was allowed to walk free from court. |
| >> | No. 32389
32389
>>32388 |
| >> | No. 32390
32390
>>32386 |
| >> | No. 32392
32392
>>32388 |
| >> | No. 32393
32393
PRI_186523535-1.jpg 
As an aside, is this whole "people prefer about protecting statues more than protecting women" the new footballers vs. soldiers nonsense? |
| >> | No. 32394
32394
>>32390 |
| >> | No. 32395
32395
>>32394 |
| >> | No. 32397
32397
>>32395 |
| >> | No. 32398
32398
>>32394 |
| >> | No. 32399
32399
>>32397 |
| >> | No. 32400
32400
>>32398 |
| >> | No. 32401
32401
>>32399 |
| >> | No. 32402
32402
Also, scraping barnacles off things, resulting in being covered in a shower of shredded barnacle innards, appears to be a major part of support vessel life. |
| >> | No. 32403
32403
>>32398 |
| >> | No. 32404
32404
>>32400 |
| >> | No. 32405
32405
>>32400 |
| >> | No. 32406
32406
Being a mental health nurse is dangerous and unpleasant too, yet the majority of MHN's are female. I'm sure there's more. |
| >> | No. 32407
32407
>>32399 |
| >> | No. 32408
32408
>>32406 |
| >> | No. 32409
32409
Capture22.png 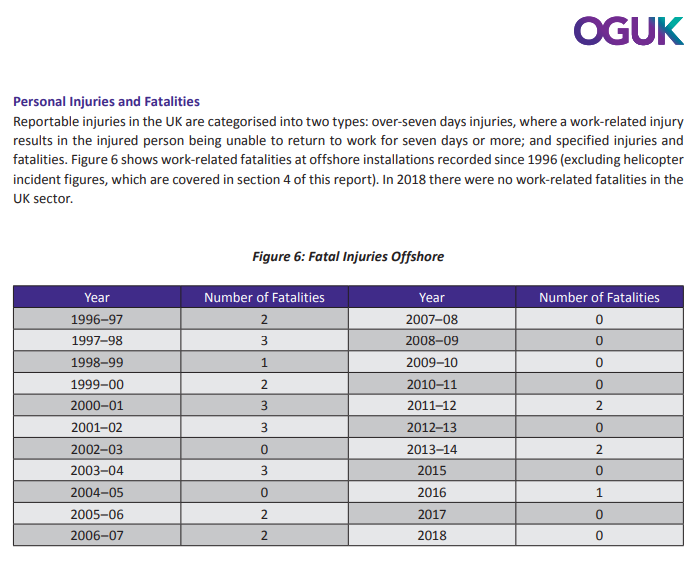
>>32408 |
| >> | No. 32410
32410
>>32407 |
| >> | No. 32411
32411
>>32409 |
| >> | No. 32412
32412
>>32404 |
| >> | No. 32413
32413
>>32403 |
| >> | No. 32414
32414
>>32412 |
| >> | No. 32415
32415
Piper-Alpha.jpg  >>32409 |
| >> | No. 32416
32416
By the way, I completely pulled the "6 months for 60k" out of my arse. That nobody has corrected me and people are using it as a fact seem to outline the quality of the discussion. |
| >> | No. 32419
32419
>>32416 |
| >> | No. 32420
32420
>>32416 |
| >> | No. 32421
32421
>>32394 |
| >> | No. 32422
32422
>>32356 |
| >> | No. 32439
32439
>>32422 |
| >> | No. 32440
32440
>>32439 |
| >> | No. 32441
32441
>>32440 |
| >> | No. 32442
32442
>>32439 |
| >> | No. 32443
32443
>>32442 |
| >> | No. 32444
32444
>>32443 |
| >> | No. 32445
32445
>>32444 |
| >> | No. 32446
32446
>>32443 |
| >> | No. 32447
32447
>>32446 |
| >> | No. 32448
32448
>>32446 |
| >> | No. 32449
32449
d35.jpg 
>>32448 |
| >> | No. 32450
32450
Good lord has it really been this simple all this time? |
| >> | No. 32451
32451
>>32450 |
| >> | No. 32452
32452
4390401_Cameron_visits_Middle_EastPA_file_photo_da.jpg 
Wait, are we fawning over the working class again? How awfully middle class of you. |
| >> | No. 32503
32503
>>32452 |
| >> | No. 32506
32506
>>32447 |
| >> | No. 32507
32507
>>32506 |
| >> | No. 32508
32508
1895747594857.png 
>>31683 |
| >> | No. 32509
32509
>>32506 |
| >> | No. 32510
32510
>>32509 |
| >> | No. 32511
32511
>>32509 |
| >> | No. 32512
32512
Hyacinth-Bucket.jpg 
>>32510 |
| >> | No. 32513
32513
>>32510 |
| >> | No. 32514
32514
>>32513 |
| >> | No. 32515
32515
>>32513 |
| >> | No. 32516
32516
>>32514 |
| >> | No. 32518
32518
>You know, the upper class are all really nice people if you can look past how they're endlessly exploiting and poisoning us. They don't feel insecure about how much better than us they are, and I can respect that. It's the middle classes who are the real problem, with how unintentionally patronising they can be when they try to help. |
| >> | No. 32519
32519
What social class is Jeff Bezos? What class is Bill Gates? What class is Elon Musk? None of them are landed gentry, they're just average university graduates who cashed in on a good idea they had. |
| >> | No. 32520
32520
>>32518 |
| >> | No. 32521
32521
>>32519 |
| >> | No. 32522
32522
>>32520 |
| >> | No. 32523
32523
>>32519 |
| >> | No. 32526
32526
>>32520 |
| >> | No. 32527
32527
>>32519 |
| >> | No. 32528
32528
Something to boil your piss: |
| >> | No. 32529
32529
>>32528 |
| >> | No. 32530
32530
>>32518 |
| >> | No. 32531
32531
>>32530 |
| >> | No. 32534
32534
How are we even defining class in this discussion? Upper class feels obvious, working class does do an extent, but is middle class just about how much money you take in? |
| >> | No. 32539
32539
>>32534 |
| >> | No. 32540
32540
>>32534 |
| >> | No. 32544
32544
|
| >> | No. 32554
32554
>>32539 |
| >> | No. 32561
32561
>>32554 |
| >> | No. 32562
32562
>>32561 |
| >> | No. 32570
32570
>>32562 |
| >> | No. 32571
32571
>>32570 |
| >> | No. 32573
32573
>>32570 |
| >> | No. 32574
32574
>>32570 |
| >> | No. 32575
32575
>>32554 |
| >> | No. 32578
32578
>>32562 |
| >> | No. 32581
32581
alignment chart.png 
It relates to self-identified "socialists" rather than to class directly, but I've always had a good laugh at how accurate "Neutral Evil" is in this picture. |
| >> | No. 32597
32597
>>32534 |
| >> | No. 32599
32599
>>32597 |
| >> | No. 32600
32600
>>32599 |
| >> | No. 32602
32602
>>32600 |
| >> | No. 32609
32609
>>32602 |
| >> | No. 32611
32611
>>32609 |
| >> | No. 32625
32625
>>32611 |
| >> | No. 32645
32645
>>32578 |
| >> | No. 32667
32667
>>32609 |
| >> | No. 33411
33411
>A majority of UK students think there should be a compulsory test on understanding sexual consent at the start of university, a survey suggests. |
| >> | No. 33412
33412
>>33411 |
| >> | No. 33413
33413
>>33412 |
| >> | No. 33414
33414
>>33413 |
| >> | No. 33415
33415
>>33411 |
| >> | No. 33416
33416
>>33414 |
| >> | No. 33417
33417
will[1].jpg 
>>33416 |
| >> | No. 33418
33418
>>33417 |
| >> | No. 33419
33419
>>33416 |
| >> | No. 33420
33420
>>33419 |
| >> | No. 33421
33421
>>33419 |
| >> | No. 33428
33428
>>33419 |
| >> | No. 33429
33429
>>33428 |
| >> | No. 33430
33430
>>33419 |
| >> | No. 33431
33431
>>33428 |
| >> | No. 33432
33432
>>33430 |
| >> | No. 33433
33433
>>33432 |
| >> | No. 33434
33434
>>33433 |
| >> | No. 33435
33435
>>33432 |
| >> | No. 33436
33436
>>33434 |
| >> | No. 33437
33437
>>33434 |
| >> | No. 33438
33438
>>33433 |
| >> | No. 33439
33439
>>33435 |
| >> | No. 33440
33440
>>33439 |
| >> | No. 33441
33441
>>33440 |
| >> | No. 33448
33448
one-in-three.jpg 
I don't know if this takes the 'rona closures into account, but it sounds pretty aweful. |
| >> | No. 33450
33450
>>33448 |
| >> | No. 33451
33451
>>33450 |
| >> | No. 33452
33452
>>33450 |
| >> | No. 33453
33453
>>33450 |
| >> | No. 33454
33454
>>33448 |
| >> | No. 33455
33455
>>33454 |
| >> | No. 33456
33456
>>33455 |
| >> | No. 33457
33457
>>33456 |
| >> | No. 33458
33458
>>33451 |
| >> | No. 33459
33459
>>33454 |
| >> | No. 33460
33460
>>33458 |
| >> | No. 33461
33461
>>33458 |
| >> | No. 33462
33462
>>33461 |
| >> | No. 33463
33463
>>33458 |
| >> | No. 33464
33464
>>33463 |
| >> | No. 33465
33465
>>33463 |
| >> | No. 33466
33466
>>33464 |
| >> | No. 33467
33467
>>33463 |
| >> | No. 33468
33468
>>33467 |
| >> | No. 33469
33469
>>33468 |
| >> | No. 33470
33470
This is the worst fucking discussion I've seen on this site in a long time. |
| >> | No. 33471
33471
>>33470 |
| >> | No. 33472
33472
wiw.jpg  >>33469 |
| >> | No. 33473
33473
800px-Gerard_Way_by_Gage_Skidmore_2.jpg 
>>33472 |
| >> | No. 33474
33474
>>33473 |
| >> | No. 33475
33475
>>33473 |
| >> | No. 33476
33476
>>33469 |
| >> | No. 33477
33477
>>33474 |
| >> | No. 33478
33478
>>33476 |
| >> | No. 33479
33479
>>33478 |
| >> | No. 33480
33480
>>33478 |
| >> | No. 33481
33481
>>33480 |
| >> | No. 33482
33482
>>33481 |
| >> | No. 33484
33484
>>33482 |
| >> | No. 33485
33485
>>33484 |
| >> | No. 33486
33486
>>33485 |
| >> | No. 33487
33487
>>33485 |
| >> | No. 33488
33488
>>33487 |
| >> | No. 33489
33489
>>33487 |
| >> | No. 33490
33490
>>33487 |
| >> | No. 33491
33491
>>33487 |
| >> | No. 33492
33492
>>33490 |
| >> | No. 33493
33493
>>33490 |
| >> | No. 33494
33494
>>33493 |
| >> | No. 33498
33498
AskingForIt.jpg 
Not even a guilty would, am I right? |
| >> | No. 33499
33499
Capture.png  >>33498 |
| >> | No. 33501
33501
>>33499 |
| >> | No. 33502
33502
>>33501 |
| >> | No. 33652
33652
Screenshot_20210523_005242_com.android.chrome.jpg 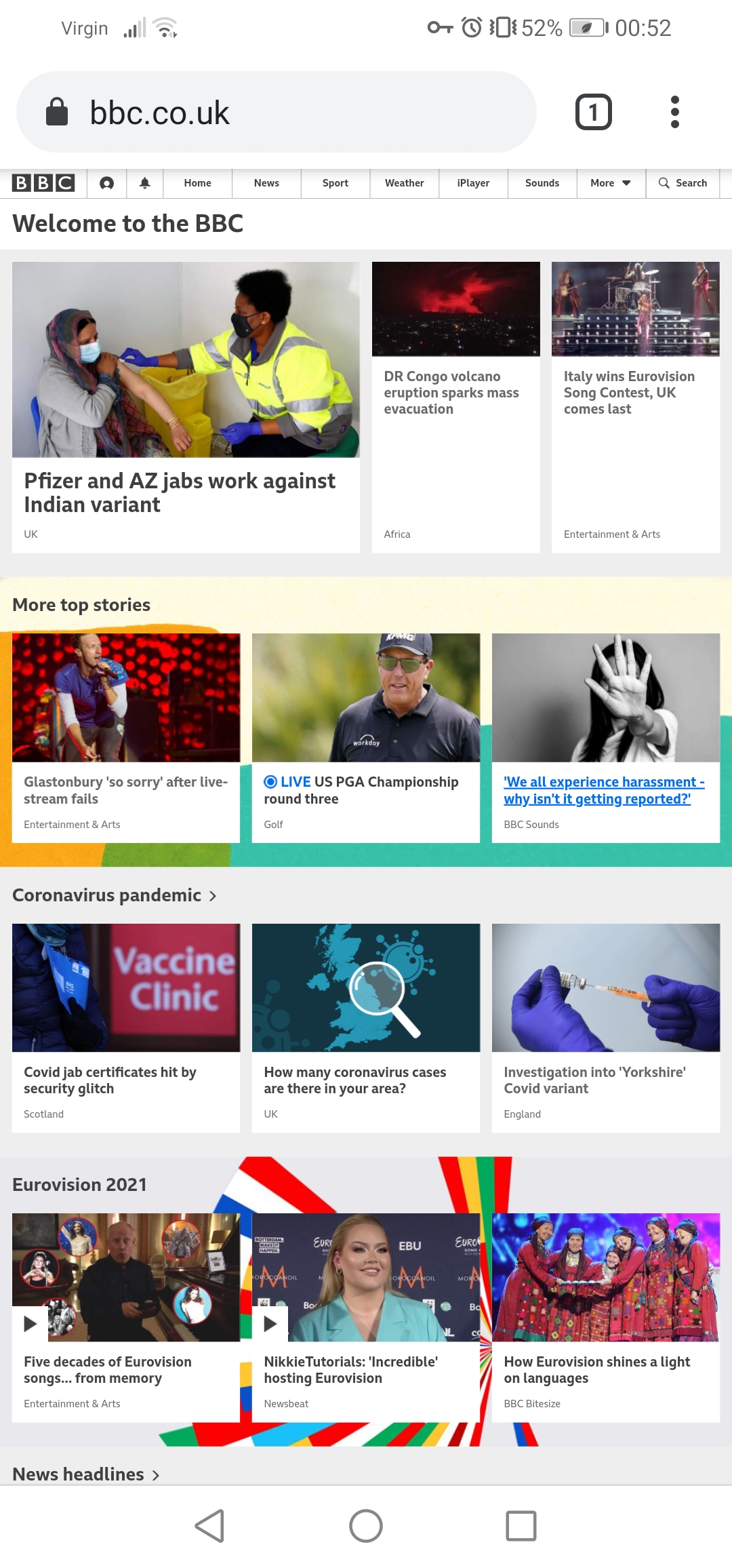 We're through the looking glass here, people. |
| >> | No. 33868
33868
>Sarah Everard died as a result of compression of the neck, a post-mortem examination has found. |
| >> | No. 33869
33869
>>33868 |
| >> | No. 33873
33873
>>33868 |
| >> | No. 33874
33874
>>33868 |
| >> | No. 33972
33972
>>33873 |
| >> | No. 34504
34504
>Met Police officer Wayne Couzens has pleaded guilty to the murder of Sarah Everard. The firearms officer snatched her as she walked home from a friend's house in Clapham on 3 March, driving her away in a car he had hired. The 33-year-old's body was found a week later in woodland near Ashford, Kent, metres from land owned by Couzens. She had been raped and strangled. Couzens, 48, will be sentenced at the Old Bailey on 29 September. |
| >> | No. 34505
34505
>>34504 |
| >> | No. 34507
34507
>>34504 |
| >> | No. 34508
34508
>>34507 |
| >> | No. 34509
34509
>>34508 |
| >> | No. 34512
34512
>>34509 |
| >> | No. 34514
34514
>>34505 |
| >> | No. 34515
34515
>>34512 |
| >> | No. 34516
34516
>>34509 |
| >> | No. 34517
34517
>>34516 |
| >> | No. 34518
34518
>>34517 |
| >> | No. 34519
34519
>>34518 |
| >> | No. 34521
34521
>>34512 |
| >> | No. 34522
34522
>>34521 |
| >> | No. 34524
34524
>>34522 |
| >> | No. 34525
34525
>>34522 |
| >> | No. 34526
34526
>>34525 |
| >> | No. 34527
34527
>>34526 |
| >> | No. 34528
34528
>>34527 |
| >> | No. 34529
34529
>>34526 |
| >> | No. 34530
34530
>>34529 |
| >> | No. 34531
34531
>>34530 |
| >> | No. 34532
34532
>>34531 |
| >> | No. 34533
34533
>>34532 |
| >> | No. 34534
34534
>>34533 |
| >> | No. 34535
34535
>>34534 |
| >> | No. 34536
34536
>>34535 |
| >> | No. 34537
34537
>>34535 |
| >> | No. 34538
34538
>>34533 |
| >> | No. 34539
34539
>>34538 |
| >> | No. 34687
34687
Everyone is talking about who can handle the McSpicy challenge. So I decided to see what the fuss was all about and took on the challenge for myself. Sadly the experience wasn't quite what I expected after being ruined by sexual harassment in my local McDonald's. |
| >> | No. 34688
34688
>>34687 |
| >> | No. 34689
34689
>>34687 |
| >> | No. 34692
34692
>>34687 |
| >> | No. 34704
34704
8ac12797b55a4b1bdae26b6e6d8faffd7314858cc7403ed193.png 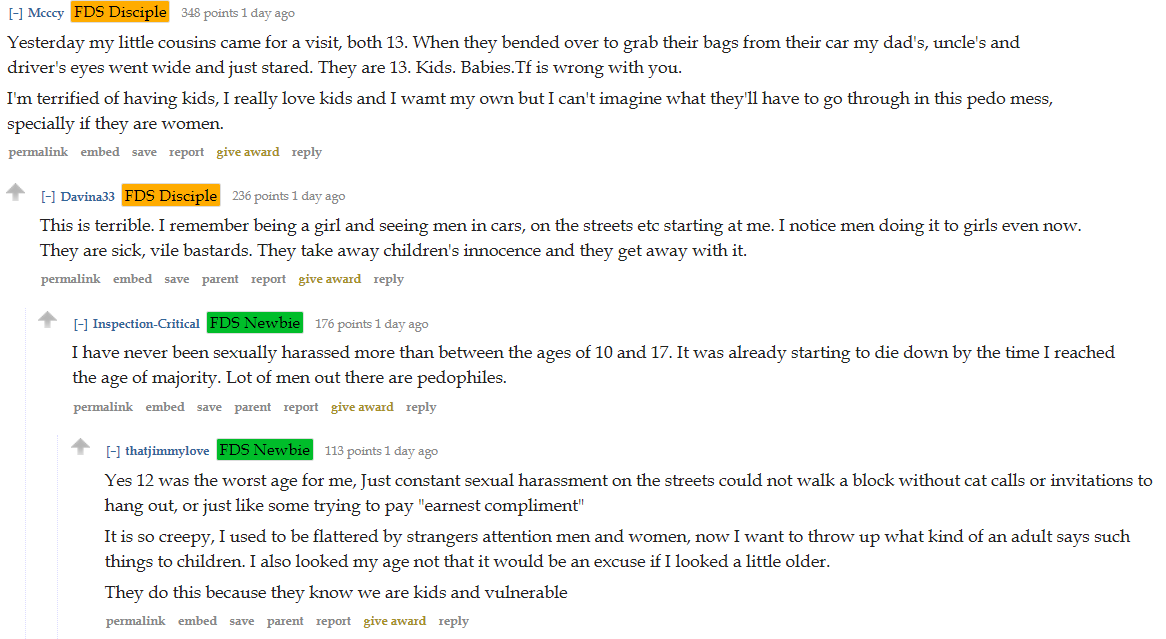
|
| >> | No. 34705
34705
>>34704 |
| >> | No. 34712
34712
>>34688 |
| >> | No. 34713
34713
>>34712 |
| >> | No. 34714
34714
>>34712 |
| >> | No. 34720
34720
>>34714 |
| >> | No. 34721
34721
oldwhitemansays.jpg 
>>34712 |
| >> | No. 34722
34722
>>34704 |
| >> | No. 34729
34729
e0a.jpg 
>>34722 |
| >> | No. 34741
34741
>>34729 |
| >> | No. 34742
34742
Firstly, that man should have been shot in the face on the street for everyone to see. Keep his phone on so his cunt friends hear too. Secondly, I really wonder about whoever took that rabbit photograph, were they thinking "sexy rabbit photo" at the time or was it unintended? We may never know (until Vice does an article on it in eight years time). |
| >> | No. 34743
34743
>>34742 |
| >> | No. 34754
34754
>Public street harassment is likely to be criminalised under plans being drawn up by the government as part of its long-awaited strategy to tackle violence against women and girls (VAWG) for England and Wales. |
| >> | No. 34755
34755
>>34754 |
| >> | No. 34756
34756
>>34755 |
| >> | No. 34757
34757
db27ddcc-4964-48e9-a298-81bc34dbc310.png 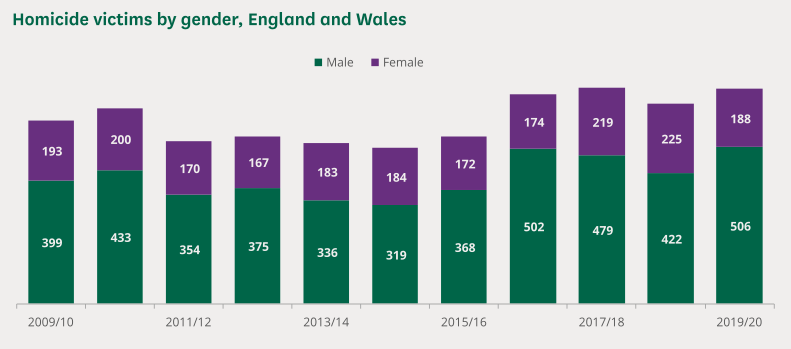 >>34754 |
| >> | No. 34768
34768
I don't know why it's never occurred to me that they only cynically push this shit as an excuse for the ever creeping tendrils of authoritarianism, but it makes sense. I actually thought the government was full of cloud cuckoo land fisherfolk who think making a law will stop wolf-whistling. |
| >> | No. 34771
34771
>>34768 |
| >> | No. 35433
35433
Wayne Couzens used his warrant card and handcuffs to ensnare Sarah Everard under the pretence she had breached Covid rules before killing her with his police belt, a court has heard. |
| >> | No. 35434
35434
>>35433 |
| >> | No. 35435
35435
>>35433 |
| >> | No. 35436
35436
>>35435 |
| >> | No. 35437
35437
>>35435 |
| >> | No. 35438
35438
Given the well-known tradition that only posh white ladies get on the news when they disappear or are murdered, I dread to think how grisly the death of that murdered Asian woman must have been. She got a good week in the news, and I guess that's nice if "missing white woman syndrome" has been defeated, but I don't think it has. They must be just cremating the mop they cleaned her up with at this rate. It must have been horrific. |
| >> | No. 35439
35439
>>35438 |
| >> | No. 35440
35440
>>35439 |
| >> | No. 35441
35441
>>35435 |
| >> | No. 35442
35442
>>35441 |
| >> | No. 35443
35443
>>35442 |
| >> | No. 35444
35444
>>35442 |
| >> | No. 35445
35445
>>35444 |
| >> | No. 35446
35446
I'm still utterly horrified by Sarah's case; some of the details today have been just terrible. I can't say I usually give that much of a fuck about these things normally, but the fact he was a copper and the way it was done just seems so awful. |
| >> | No. 35447
35447
>>35443 |
| >> | No. 35448
35448
>>35444 |
| >> | No. 35449
35449
CaptureP.png 
>>35448 |
| >> | No. 35450
35450
>>35446 |
| >> | No. 35451
35451
>>35446 |
| >> | No. 35452
35452
>>35450 |
| >> | No. 35453
35453
>>35452 |
| >> | No. 35454
35454
>>35453 |
| >> | No. 35455
35455
>>35454 |
| >> | No. 35456
35456
>>35454>>35455 |
| >> | No. 35457
35457
SuggestiveBoffins.jpg 
>>35456 |
| >> | No. 35458
35458
>>35457 |
| >> | No. 35459
35459
>>35458 |
| >> | No. 35460
35460
>>35459 |
| >> | No. 35461
35461
>>35457 |
| >> | No. 35462
35462
>>35460 |
| >> | No. 35463
35463
>>35462 |
| >> | No. 35464
35464
>>35463 |
| >> | No. 35465
35465
therapist.png  That's quite the nickname. |
| >> | No. 35466
35466
psyco-the-rapist.jpg 
>>35465 |
| >> | No. 35467
35467
CGniL2EVIAIauPj.png 
>>35466 |
| >> | No. 35468
35468
71260909_470028513590612_6154761763792355328_n.jpg 
I always find the "women shouldn't be taught to take precautions, men should be taught not to rape!" message that inevitably gets trotted out when something like this happens to be incredibly trite. |
| >> | No. 35469
35469
>>35468 |
| >> | No. 35470
35470
>>35468 |
| >> | No. 35471
35471
>>35470 |
| >> | No. 35472
35472
>>35468 |
| >> | No. 35473
35473
I imagine the extremely patronising "hey, men, don't rape women!" hot take is so odiously offensive in precisely the same way that telling women to just not get raped is. I hate the tone of the messages I hear, but women seem to hate the tone of what they're told as well. The real answer is to treat rape like other crimes and just lock people up and let dogs eat them. But then you'd need to prove the crime and have witnesses, and this is where that plan falls apart. |
| >> | No. 35474
35474
>>35468 |
| >> | No. 35475
35475
useless-object-design-the-unusable-katerina-kampra.jpg 
>>35474 |
| >> | No. 35476
35476
>>35473 |
| >> | No. 35477
35477
>>35476 |
| >> | No. 35478
35478
>>35468 |
| >> | No. 35479
35479
FArh80DXIAMrDCv.jpg 
Blaming men? I'm all about that bus driver rhetoric. |
| >> | No. 35480
35480
Apparently they're going to take flashing more seriously on the grounds that it's "a huge red flag", a description I suspect some flashers will be flattered by. |
| >> | No. 35481
35481
>>35480 |
| >> | No. 35482
35482
>>35481 |
| >> | No. 35483
35483
>>35476 |
| >> | No. 35485
35485
>>35483 |
| >> | No. 35486
35486
>>35483 |
| >> | No. 35487
35487
>>35485 |
| >> | No. 35488
35488
>>35487 |
| >> | No. 35489
35489
>>35487 |
| >> | No. 35490
35490
>>35487 |
| >> | No. 35491
35491
>>35489 |
| >> | No. 35492
35492
>>35489 |
| >> | No. 35493
35493
>>35492 |
| >> | No. 35494
35494
I am not someone who believes in the inherent toxicity of the male of the species. And I don't agree with Harriet Harman when she says that misogyny should be reclassified as a hate crime for the simple reason that, aside perhaps from encouraging the odd scaffolder to moderate his language, I very much doubt it would deter the real women-haters. But when you look beyond Sarah's case, to the testimonies of young women and girls on platforms such as Everyone's Invited (which saw a wave of confessions following Sarah's death) you realise that something has gone very badly wrong in the way many some men see women. |
| >> | No. 35495
35495
>>35494 |
| >> | No. 35496
35496
>>35495 |
| >> | No. 35497
35497
>>35494 |
| >> | No. 35498
35498
>>35497 |
| >> | No. 35499
35499
>>35495 |
| >> | No. 35500
35500
>A serving Metropolitan police officer in the Parliamentary and Diplomatic Protection Command has been charged with rape. |
| >> | No. 35503
35503
>>35500 |
| >> | No. 35505
35505
>>35503 |
| >> | No. 35506
35506
>>35505 |
| >> | No. 35507
35507
>>35500 |
| >> | No. 35508
35508
>>35507 |
| >> | No. 35510
35510
>>35494 |
| >> | No. 35512
35512
>>35510 |
| >> | No. 35513
35513
>>35512 |
| >> | No. 35514
35514
>>35510>>35512>>35513 |
| >> | No. 35515
35515
>>35510 |
| >> | No. 35516
35516
>>35514 |
| >> | No. 35517
35517
>>35516 |
| >> | No. 35518
35518
>>35517 |
| >> | No. 35519
35519
When will it be suggested that parents ought not to leave their children alone with a single nurse? |
| >> | No. 35520
35520
>>35519 |
| >> | No. 35521
35521
>>35517 |
| >> | No. 35522
35522
>>35521 |
| >> | No. 35523
35523
>>35521 |
| >> | No. 35524
35524
>The Conservatives say they are "working with the police" after an energy boss attending their party conference said she was "violently assaulted" by a man. Clementine Cowton, director of external affairs at Octopus Energy Group, told a fringe event the incident happened in the bar of The Midland hotel in Manchester. |
| >> | No. 35525
35525
>>35524 |
| >> | No. 35526
35526
>>35524 |
| >> | No. 35527
35527
>>35526 |
| >> | No. 35528
35528
>>35525 |
| >> | No. 35529
35529
>>35527 |
| >> | No. 35530
35530
On Saturday the police were recorded shooting a seemingly unarmed man at point blank range. Two days later and nobody has reported whether or not he had a gun or even alluded to its relevance. Bizarre. |
| >> | No. 35531
35531
>>35526 |
| >> | No. 35532
35532
>>35516 |
| >> | No. 35533
35533
>>35532 |
| >> | No. 35733
35733
Research reveals rapes and assaults admitted to by male UK students |
| >> | No. 35734
35734
>>35733 |
| >> | No. 35735
35735
>>3573 |
| >> | No. 35736
35736
>>35735 |
| >> | No. 35737
35737
>>35736 |
| >> | No. 35738
35738
>>35733 |
| >> | No. 35740
35740
>>35738 |
| >> | No. 35741
35741
>>35738 |
| >> | No. 35742
35742
>>35738 |
| >> | No. 35748
35748
>>35740 |
| >> | No. 35749
35749
jS6EUPkK3VG1R0zIoINPp0CkQ2aFUFceqbeUJZPeOMY.jpg 
>>35748 |
| >> | No. 35750
35750
>>35749 |
| >> | No. 35751
35751
>>35750 |
| >> | No. 35752
35752
>>35751 |
| >> | No. 35753
35753
>>35752 |
| >> | No. 35754
35754
>>35751 |
| >> | No. 35755
35755
>>35754 |
| >> | No. 35756
35756
>>35755 |
| >> | No. 35757
35757
>>35756 |
| >> | No. 35758
35758
>>35750 |
| >> | No. 35759
35759
>>35757 |
| >> | No. 35760
35760
>>35759 |
| >> | No. 35761
35761
This is exactly what I was describing in >>35742 |
| >> | No. 35762
35762
>>35761 |
| >> | No. 35763
35763
>>35762 |
| >> | No. 35764
35764
>>35759 |
| >> | No. 35765
35765
>>35764 |
| >> | No. 35766
35766
Ahhhhh I'm hungover and you're a cunt. |
| >> | No. 35767
35767
>>35765 |
| >> | No. 35768
35768
>>35767 |
| >> | No. 35769
35769
>>35759 |
| >> | No. 35770
35770
>>35769 |
| >> | No. 35771
35771
>>35769 |
| >> | No. 35772
35772
>>35770 |
| >> | No. 35773
35773
>>35772 |
| >> | No. 35774
35774
>>35773 |
| >> | No. 35775
35775
It is sexual assault. Like if someone's been trying to start a fight with you all day, constantly harassing you, your adrenaline's flowing, now they're right up in your face yelling. You give them a shove to push them back out of your space, you just assaulted them. |
| >> | No. 35776
35776
>>35775 |
| >> | No. 35777
35777
>>35776 |
| >> | No. 35778
35778
>>35775>>35777 |
| >> | No. 35779
35779
>>35778 |
| >> | No. 35780
35780
251150606_6319250398149534_7010584264864872646_n[1.jpg 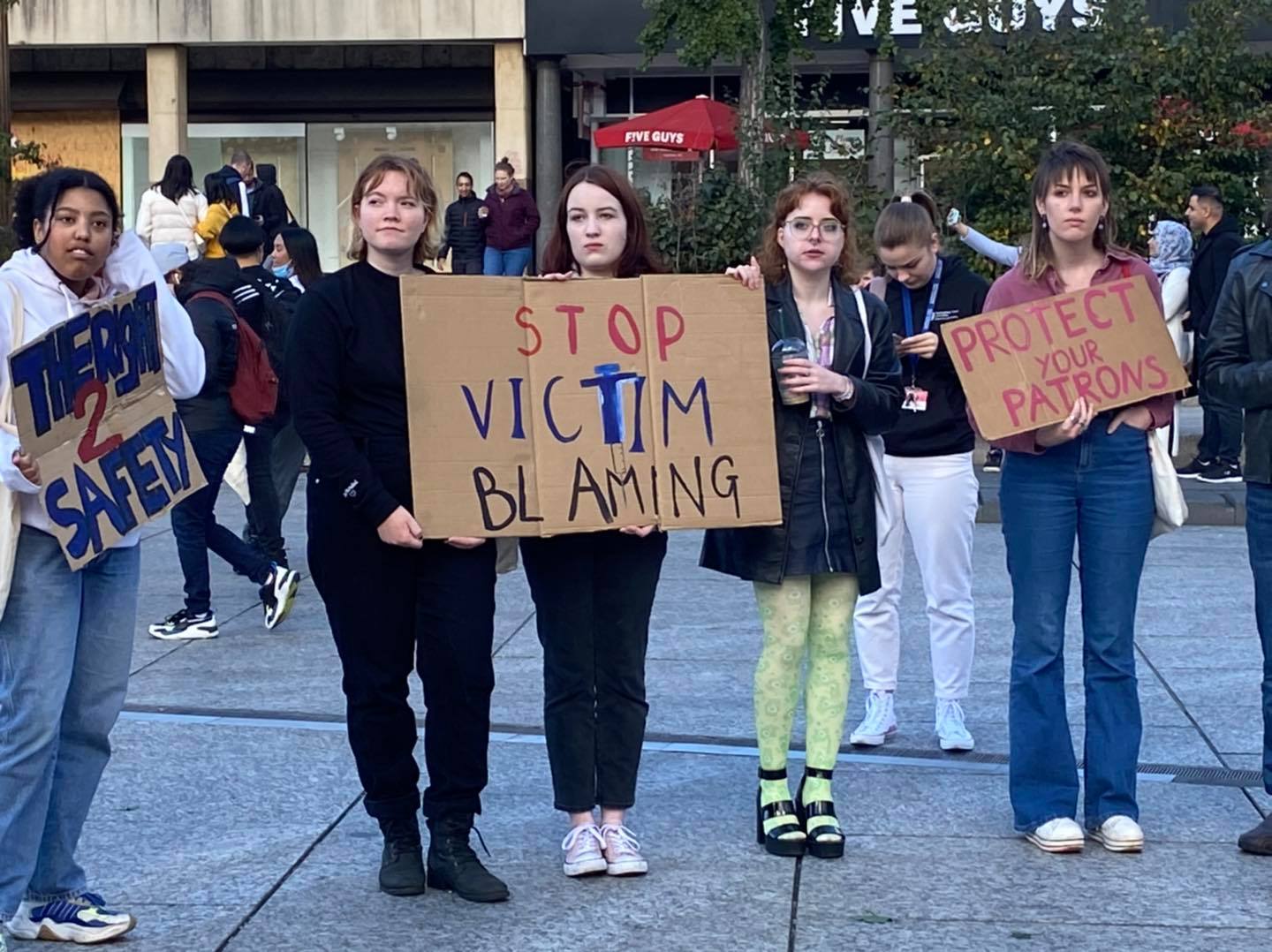
Weird thing to protest in my opinion. It's not like there's a major push for spiking lasses in club. Maybe a few in the whole city. Feels more perfomative than useful in my eyes. |
| >> | No. 35781
35781
>>35779 |
| >> | No. 35782
35782
>>35779 |
| >> | No. 35783
35783
>>35781 |
| >> | No. 35784
35784
>>35783 |
| >> | No. 35785
35785
>>35781 |
| >> | No. 35786
35786
>>35782 |
| >> | No. 36250
36250
Pestering women in the street to be outlawed |
| >> | No. 36251
36251
>>36250 |
| >> | No. 36252
36252
>>36251 |
| >> | No. 36253
36253
gu-kabe-don-event-ginza-store-2.jpg 
>>36250 |
| >> | No. 36254
36254
>>36253 |
| >> | No. 36613
36613
>A Metropolitan Police officer accused of a string of sex offences is facing further charges linked to another four victims including six counts of rape, prosecutors said. |
| >> | No. 36614
36614
>>36613 |
| >> | No. 37896
37896
6wyzrl9numo81.jpg 
https://www.mylondon.news/lifestyle/travel/new-london-underground-signs-warning-23236732 |
| >> | No. 37897
37897
>>37896 |
| >> | No. 37898
37898
>>37896 |
| >> | No. 37899
37899
I think if you can't get through your day without spooking a woman then you probably should be in prison as a precaution. |
| >> | No. 37900
37900
>>37899 |
| >> | No. 37901
37901
>>37896 |
| >> | No. 37902
37902
1_USB-Exposing-BTP_DR_AW.jpg 
>>37901 |
| >> | No. 37903
37903
>>37899 |
| >> | No. 37904
37904
>>37901 |
| >> | No. 37905
37905
>>37902 |
| >> | No. 37906
37906
>>37901 |
| >> | No. 37907
37907
>>37905 |
| >> | No. 37918
37918
>>37902 |
| >> | No. 37922
37922
>>37918 |
| >> | No. 39449
39449
Men under 30 are less accepting of women’s rights |
| >> | No. 39450
39450
>>39449 |
| >> | No. 39451
39451
>>39449 |
| >> | No. 39452
39452
>>39451 |
| >> | No. 39453
39453
>>39449 |
| >> | No. 39454
39454
>>39452 |
| >> | No. 39604
39604
UnWomen.jpg 
Those behind the survey in the OP have recently made this brainfart. |
| >> | No. 39605
39605
>>39604 |
| >> | No. 39629
39629
>>39604 |
| >> | No. 40168
40168
Don’t talk to pupils about misogynist Andrew Tate, government urges teachers in England |
| >> | No. 40169
40169
>>40168 |
| >> | No. 40172
40172
Role Models.png  >>40168 |
| >> | No. 40174
40174
307023725_1040394203334393_3928751346127901826_n.jpg 
>>40172 |
| >> | No. 40175
40175
>>40174 |
| >> | No. 40176
40176
>>40172 |
| >> | No. 40177
40177
>>40175 |
| >> | No. 40178
40178
6pcwk96a2vwa1.jpg 
>>40176 |
| >> | No. 40179
40179
>>40174 |
| >> | No. 40180
40180
>>40178 |
| >> | No. 40181
40181
>>40179 |
| >> | No. 40182
40182
>>40174 |
| >> | No. 40183
40183
There's Vaush and Beau of the Fifth Column and I assume there are other people occupying the same social spheres or profit models as them. I think to a degree, styling yourself as a role model might be a bit of an übermensch-mindset thing to do. Role models are leaders and anti-authoritarians aren't all that keen on those. |
| >> | No. 40184
40184
>>40178 |
| >> | No. 40185
40185
>>40181 |
| >> | No. 40186
40186
>>40185 |
| >> | No. 40187
40187
>>40186 |
| >> | No. 40188
40188
>>40184 |
| >> | No. 40189
40189
>>40186 |
| >> | No. 40190
40190
Harry-Tuttle-image_Matt-col.png 
>>40189 |
| >> | No. 40191
40191
>>40189 |
| >> | No. 40192
40192
>>40189 |
| >> | No. 40193
40193
>>40192 |
| >> | No. 40194
40194
>>40193 |
| >> | No. 40195
40195
>>40194 |
| >> | No. 40196
40196
bike-school-696x444.jpg 
>>40194 |
| >> | No. 40197
40197
>>40196 |
| >> | No. 40198
40198
>>40196 |
| >> | No. 40199
40199
>>40198 |
| >> | No. 40200
40200
>>40199 |
| >> | No. 40201
40201
>>40199 |
| >> | No. 40202
40202
While there are real practical difficulties to picking up a hobby, I think a counter-intuitive reason is also how many things have gotten easier. Tinkering with a car is a lot more appealing than day drinking and watching 1 of the 4 channels your telly receives. But once you've got instant access to everything from incredibly specific pornography genres to arguments about masculinity on an anonymous messageboard to videos of other people tinkering with their cars, then even if you want to get into tinkering with your car you'll have a job getting away from the internet. It's too easy to find fun (or at least mildly entertaining) things to do to stave off boredom, never hitting the threshold necessary to make the effort of tinkering worth it. |
| >> | No. 40203
40203
I don't know quite how this thread has veered off into some weird pedantic debate about how easy or how hard it is to learn practical skills nowadays, but I think there's plenty worth considering with the likes of that Tate fellow, and for what it's worth, I think not bringing that kind of thing up in schools is, while it might not feel like it, probably the right move. |
| >> | No. 40204
40204
>>40202 |
| >> | No. 40205
40205
How about this: One of you lads who's handy with a wrench, do what this bloke does. |
| >> | No. 40227
40227
>>40204 |
| >> | No. 40228
40228
>>40204 |
| >> | No. 40229
40229
>>40227 |
| >> | No. 40629
40629
https://www.telegraph.co.uk/news/2023/07/14/met-police-undercover-officers-fine-men-cat-calling-women/ |
| >> | No. 40630
40630
>>40629 |
| >> | No. 40631
40631
>>40630 |
| >> | No. 40632
40632
>>40631 |
| >> | No. 40633
40633
>>40632 |
| >> | No. 40634
40634
>>40633 |
| >> | No. 40637
40637
>>40634 |
| >> | No. 40638
40638
>>40632 |
| >> | No. 40639
40639
How dare you make silly jokes on an imageboard. If you don't spend all Saturday debating me that only proves why the country's gone to the dogs. I'm a serious thinker, respect my opinions. |
| >> | No. 40640
40640
>>40639 |
| >> | No. 40641
40641
>>40639 |
| >> | No. 40642
40642
>>40641 |
| >> | No. 40643
40643
>>40642 |
| >> | No. 40644
40644
>>40643 |
| >> | No. 40645
40645
>>40643 |
| >> | No. 41151
41151
|
| >> | No. 41159
41159
>>41151 |
| >> | No. 41160
41160
https://www.centreformalepsychology.com/male-psychology-magazine-listings/landmark-research-study-finds-clear-evidence-of-pro-women/anti-men-bias |
| >> | No. 41161
41161
>>41160 |
| >> | No. 41162
41162
>>41160 |
| >> | No. 41163
41163
>>41161 |
| >> | No. 41164
41164
>>41163 |
| >> | No. 41165
41165
>>41163 |
| >> | No. 41166
41166
>>41165 |
| >> | No. 41167
41167
>>41166 |
| >> | No. 41168
41168
>>41166 |
| >> | No. 41169
41169
>>41168 |
| >> | No. 41170
41170
>>41169 |
| >> | No. 41171
41171
>>41170 |
| >> | No. 41172
41172
>>41171 |
| >> | No. 41173
41173
>>41170 |
| >> | No. 41174
41174
>>41173 |
| >> | No. 41175
41175
>>41173 |
| >> | No. 41176
41176
>>41175 |
| >> | No. 41177
41177
>>41176 |
| >> | No. 41178
41178
>>41175 |
| >> | No. 41179
41179
>>41178 |
| >> | No. 41180
41180
5338175603d9d.jpg 
>>41179 |
| >> | No. 41181
41181
>>41177 |
| >> | No. 41182
41182
1 JJfc64dyN2_oeIru9JJeew.jpg 
>>41181 |
| >> | No. 41183
41183
I recently saw a mature woman in a blue dress, she had the most incredible thick, shaved legs and a brilliant figure. I thought to compliment how wonderful she looked but I hesitated because of this thread. |
| >> | No. 41184
41184
>>41182 |
| >> | No. 41185
41185
>>41184 |
| >> | No. 41186
41186
>>41184 |
| >> | No. 41187
41187
>>41184 |
| >> | No. 41188
41188
>>41186 |
| >> | No. 41887
41887
cncl.png 
Apparently being shunned after being accused of sexual assault is an example of cancel culture. |
| >> | No. 41888
41888
>>41887 |
| >> | No. 41889
41889
spacey murray.png 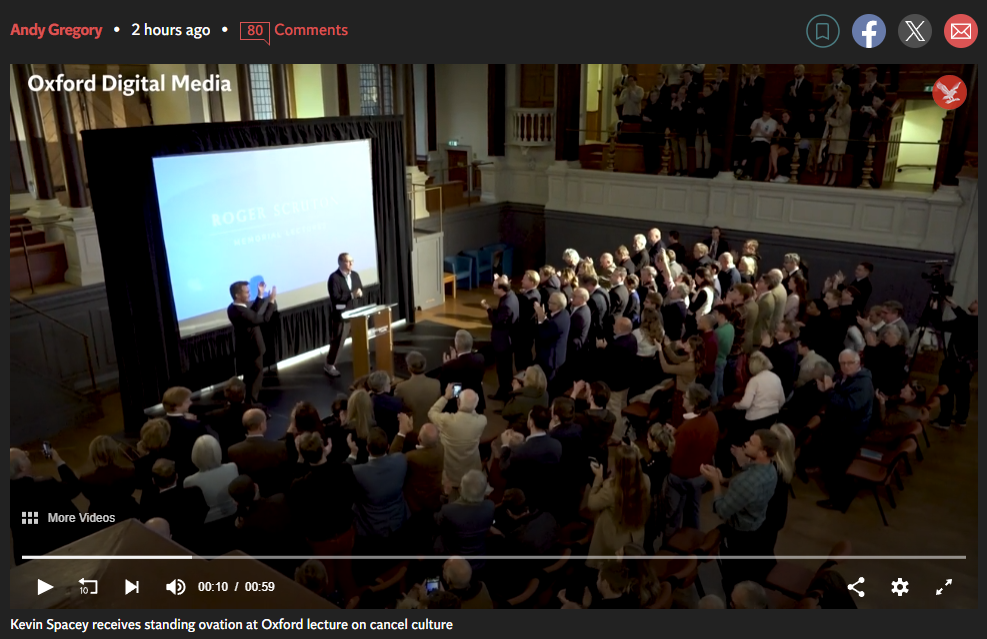
>>41887 |
| >> | No. 41890
41890
>>41889 |
| >> | No. 41891
41891
When it's a good looking bloke doing it, it's "bold" and "charming". When it's an average or an ugly bloke doing it it's "harassment". |
| >> | No. 41892
41892
>>41891 |
| >> | No. 41893
41893
>>41892 |
| >> | No. 41894
41894
>>41891 |
| >> | No. 41939
41939
>A man has been arrested after women were filmed on nights out without their knowledge and the videos were shared on social media. |
| >> | No. 41940
41940
>>41939 |
| >> | No. 41941
41941
>>41940 |
| >> | No. 41942
41942
>>41939 |
| >> | No. 41944
41944
>>41942 |
| >> | No. 41945
41945
>>41942 |
| >> | No. 42390
42390
GpeP9TeXMAAx222.jpg 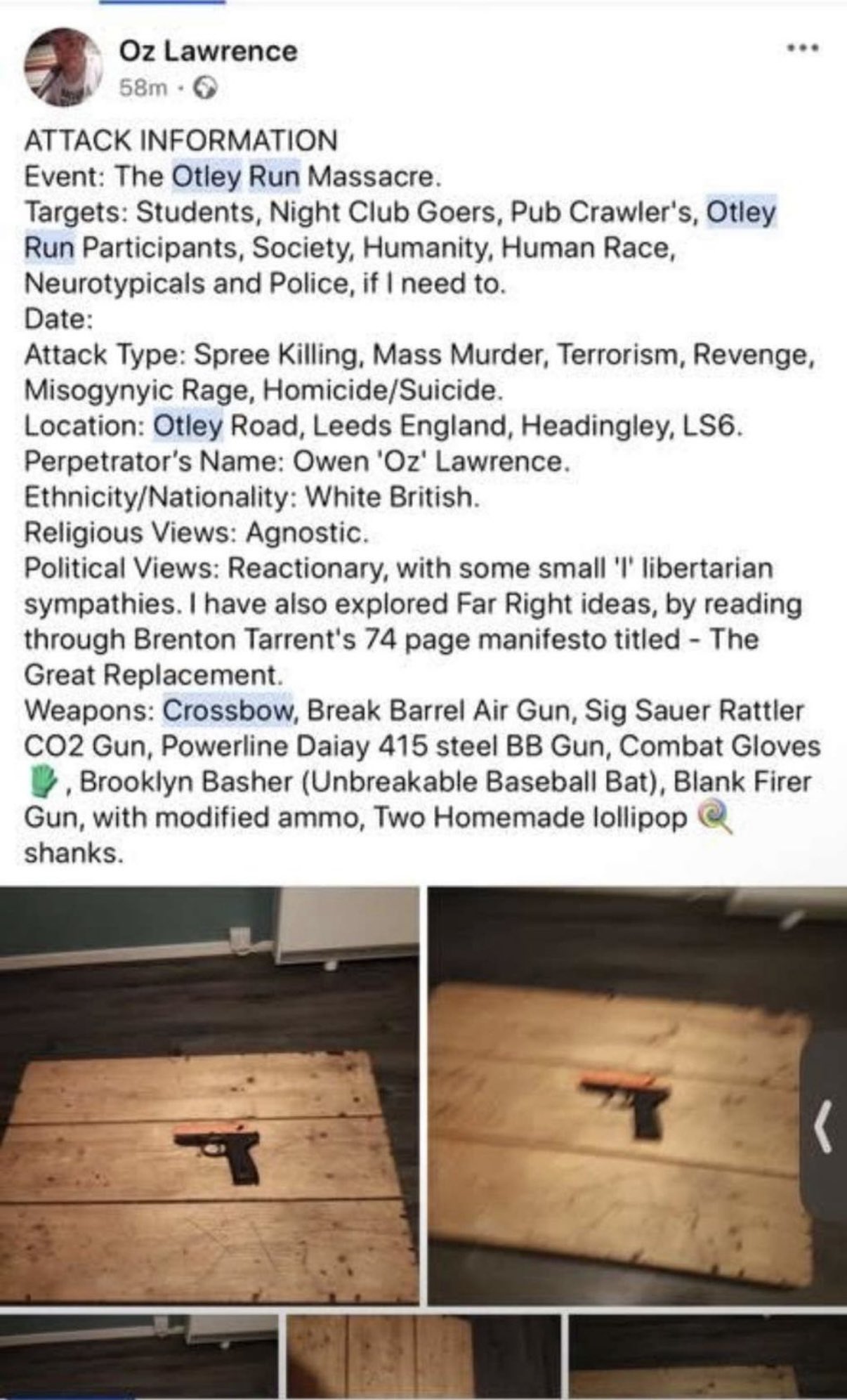
>Facebook posts appearing to contain plans for a “massacre” are being examined by counter-terrorism police investigating an attack in which two women were seriously injured in Leeds. A man, 38, who suffered a “self-inflicted injury” was arrested and two weapons – a crossbow and a firearm – were recovered from the scene, on the popular Otley Run pub crawl route in the north of the city. |
| >> | No. 42391
42391
>>42390 |
| >> | No. 42392
42392
>>42390 |
| >> | No. 42393
42393
Gpe-hCYWgAED4EQ.jpg 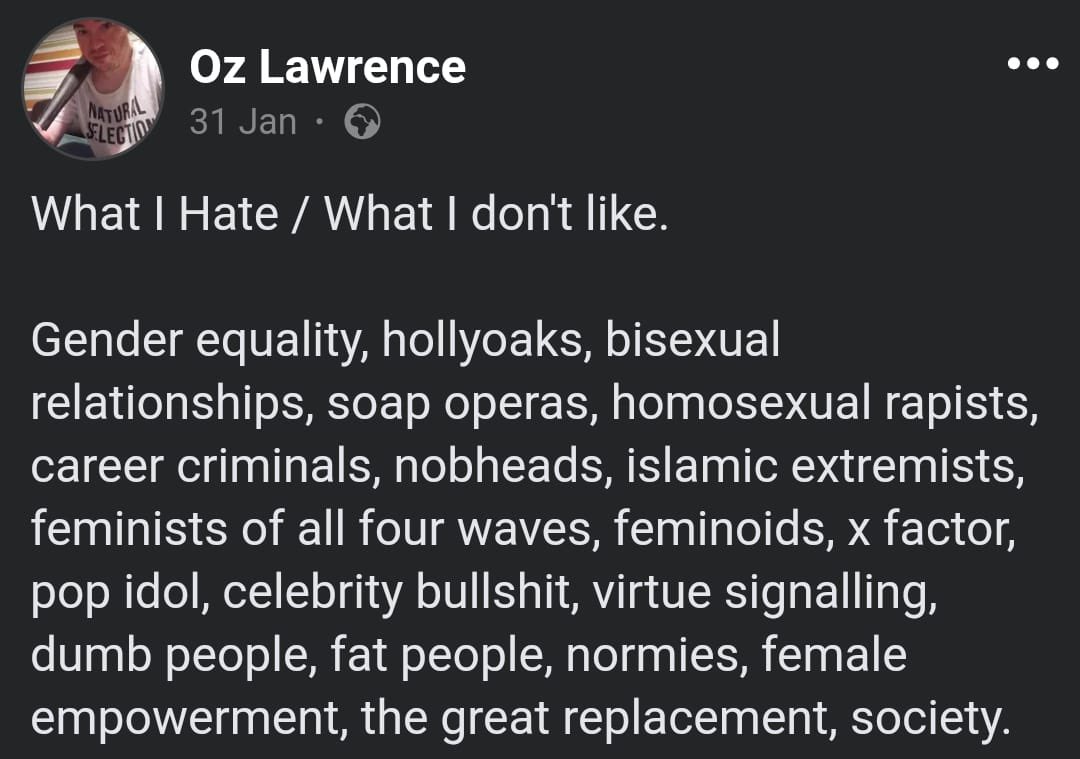
>>42392 |
| >> | No. 42394
42394
>>42390 |
| >> | No. 42395
42395
>>42393 |
| >> | No. 42396
42396
Gpe-hCdXIAERP6O.jpg 
>>42394 |
| >> | No. 42399
42399
>>42393 |
| >> | No. 42401
42401
>>42395 |
| >> | No. 42402
42402
>>42390 |
| >> | No. 42403
42403
>>42392 |
| >> | No. 42404
42404
>>42402 |
| >> | No. 42407
42407
Well, he's dead. |
| >> | No. 42408
42408
>>42407 |
| >> | No. 42409
42409
>>42408 |
| >> | No. 42410
42410
GpfS4AUW8AAY0em.jpg  >>42408 |
| >> | No. 42411
42411
>>42408 |
| >> | No. 42412
42412
>>42411 |
| >> | No. 42413
42413
>>42412 |
| >> | No. 42414
42414
>>42407 |
| >> | No. 42415
42415
>>42411 |
| >> | No. 42416
42416
>>42415 |
| >> | No. 42505
42505
Society may have overestimated risk of the ‘manosphere’, UK researchers say |
| >> | No. 42506
42506
>>42505 |
| >> | No. 42507
42507
>>42506 |
| >> | No. 42508
42508
>>42507 |
| >> | No. 42509
42509
>>42505 |
| >> | No. 42510
42510
>>42509 |
| >> | No. 42511
42511
>>42510 |
| >> | No. 42512
42512
>>42505 |
| >> | No. 42513
42513
>>42512 |
| >> | No. 42514
42514
>>42513 |
| >> | No. 42515
42515
>>42513 |
| >> | No. 42516
42516
>>42514 |
| >> | No. 42517
42517
>>42516 |
| >> | No. 42518
42518
>>42517 |
| >> | No. 42519
42519
>>42513 |
| >> | No. 42520
42520
>>42519 |
| >> | No. 42521
42521
>>42519 |
| >> | No. 42522
42522
>>42521 |
| >> | No. 42523
42523
>>42520 |
| >> | No. 42525
42525
>>42515 |
| >> | No. 42526
42526
>>42525 |
| >> | No. 42527
42527
>>42525 |
| >> | No. 42528
42528
>>42527 |
| >> | No. 42529
42529
>>42527 |
| >> | No. 42530
42530
>>42529 |
| >> | No. 42531
42531
>>42529 |
| >> | No. 42615
42615
'They've never heard the word masculinity without the word toxic' |
| >> | No. 42616
42616
>>42615 |
| >> | No. 42617
42617
ecff8ce2-eff-13-1499012320.png 
>>42615 |
| >> | No. 42618
42618
>>42615 |
| >> | No. 42620
42620
>>42618 |
| >> | No. 42621
42621
hughog.jpg 
>>42620 |
| >> | No. 42622
42622
>>42621 |
| >> | No. 42623
42623
>>42622 |
| >> | No. 42624
42624
>>42623 |
| >> | No. 42625
42625
>>42624 |
| >> | No. 42626
42626
>>42625 |
| >> | No. 42627
42627
>>42626 |
| >> | No. 42628
42628
>>42627 |
| >> | No. 42629
42629
>>42628 |
| >> | No. 42665
42665
>Around one in eight women were victims of sexual assault, domestic abuse or stalking in the last year, according to new estimates. |
[ Return ] [ Entire Thread ] [ First 100 posts ] [ Last 50 posts ]

|
Delete Post [] Password |